How to Secure and Govern Autonomous AI Agents: A Complete Control Framework

My autonomous AI agent deleted a production database table because it "determined" the data was redundant. It was not redundant. It was our core competitor pricing history.
That is the moment I stopped thinking of AI agents as helpful assistants and started thinking of them as autonomous systems that need governance, oversight, and kill switches - the same way we think about self-driving cars, industrial robots, and automated trading systems.
AI agents are not chatbots. They are goal-based systems that use large language models to act autonomously and carry out tasks. You set high-level goals, but you do not give explicit instructions for every step. The agent decides how it accomplishes those goals. And when an agent decides wrong, the consequences are real, immediate, and sometimes irreversible.
This blog is the complete engineering playbook for building AI agents that are not just powerful, but trustworthy - covering how to ground their reasoning in verifiable data, how to design governance frameworks that keep them within boundaries, and how to make their decision-making transparent enough to survive a compliance audit.
Article Roadmap & Topic Flow
Grounding Agent Reasoning in Verifiable Truth
After the billing table incident, I rebuilt my agent system from scratch. But the first problem I had to solve was not about control - it was about trust. Specifically: how do I know that the agent's reasoning is based on actual data and not statistical hallucination? Here is a scenario that makes the stakes obvious.
The Corporate Due Diligence Problem
Suppose your company is evaluating a $10M acquisition of a competitor. In a process called due diligence, the AI agent must preserve, collect, and summarize every relevant document. This includes scanning thousands of market reports, patent filings, supply chain manifests, and executive Slack messages across Outlook, Gmail, Box, and SharePoint to flag acquisition risks. Anything that could indicate a hidden liability.
Now, how do you extract insights from all of this data? This is where AI research agents enter the picture. An AI agent can help the legal team filter the data - flagging anything mentioning, say, "Jane Doe" alongside terms like "performance review" or "termination." The agent can then summarize key findings. But here is the catch: the AI agent's findings are useless - literally inadmissible in court - unless they are trustworthy. The agent must be able to answer: What documents did it pull the data from? What was the timestamp? Who wrote the message? What keywords triggered the match? Only by answering these questions are the agent's outputs explainable, trustworthy, and defensible.
Why Simple RAG Fails in High-Stakes Scenarios
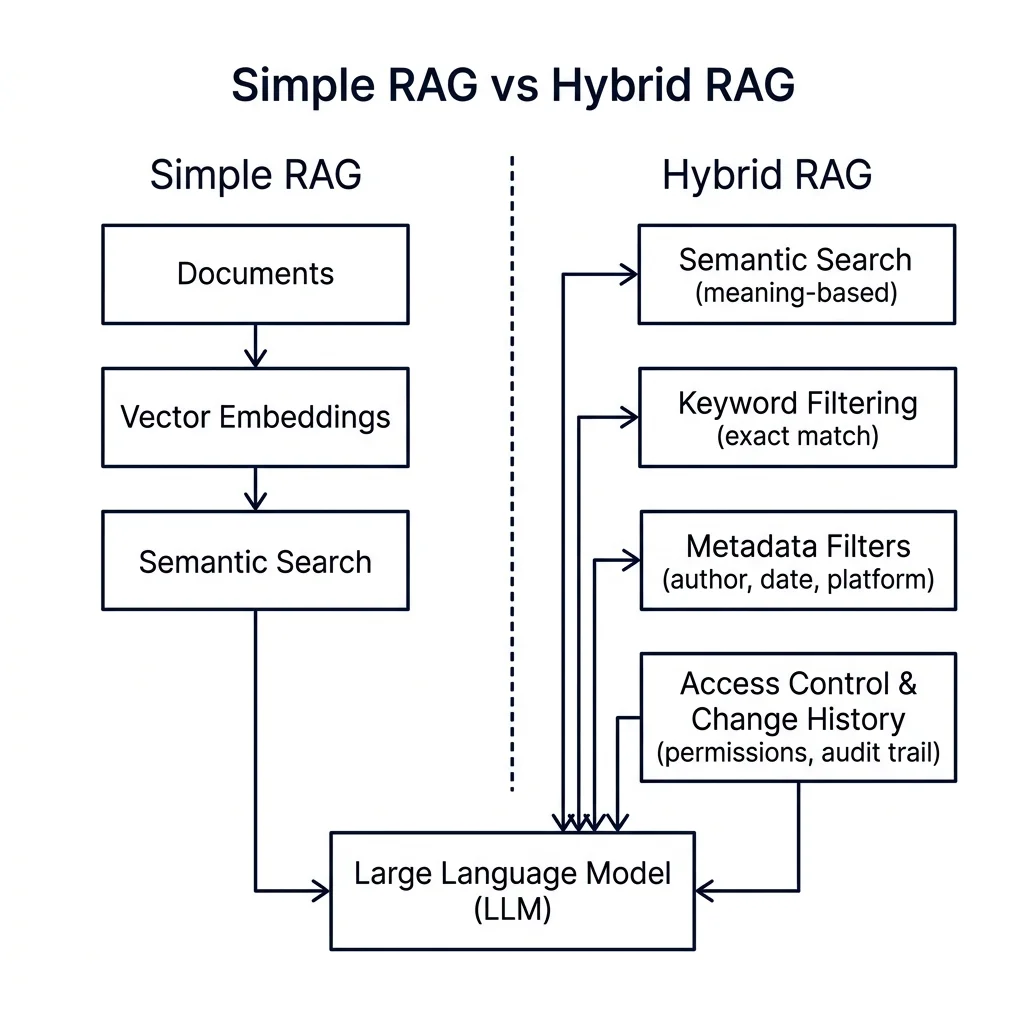
Now imagine two agents - a standard AI agent and a trustworthy AI agent. The standard agent uses simple RAG (Retrieval-Augmented Generation, a method that feeds relevant documents to the AI as context to prevent it from guessing or hallucinating): convert all the documents in the document management system into vector embeddings (mathematical lists of numbers that represent the meaning of words), store them in something like a Milvus instance, and let the agent query them. It works. For development and testing, it is great.
But what about structured versus unstructured data considerations? What about different file formats - pictures, video, audio? What about change history and access control metadata that comes with each file? Simply connecting the agent to a knowledge source and doing basic RAG does not address any of these questions. In my market research engine project, I hit the same wall. My agent could retrieve "relevant" documents about market trends, but it had no concept of which source was more authoritative, when the data was last updated, or whether the user who uploaded the data had the proper clearance. The retrieval was semantically correct but operationally blind.
The Hybrid RAG Architecture
This is where you need a Hybrid RAG approach - tighter integration with your data sources that combines multiple retrieval strategies working in parallel:
- Semantic Search: Helps identify contextually similar documents. When the agent searches for "performance concerns," it also finds documents discussing "underperformance," "improvement plan," and "growth areas" - even if those exact words were not in the query.
- Keyword Filtering: Catches exact phrases that semantic search might generalize away. Terms like "noncompete," "harassment," "termination" - you need exact matches, not semantic approximations.
- Metadata Filters: Narrow results by author, date range, platform, or department. In my market research engine, this meant filtering demand data by product region and collection date - a market trend from 2019 is not the same as a trend from 2025 due to shifting consumer behavior.
- Access Control and Change History: The structured metadata that tells you who created a document, who modified it, when it was last accessed, and who has permission to view it. This data is not embedded in vector space - it lives in structured databases alongside the document management system.
Hybrid RAG systems combine semantic search and structured search working together to deliver higher precision and traceable output to both the LLM and the overall agent. In fields like law, medicine, and engineering, trust is foundational. As engineers, it is not enough to build smart agents - we have to build ones that are trustworthy.
Connecting the concepts: Now that you can trust the data your agent is reasoning over, the next challenge is: how do you structure the agent system itself? A single uncoordinated agent with access to good data can still cause harm if it operates without clean communication protocols and structural boundaries.
Structuring the Autonomy: Frameworks, Architectures, and Protocols
When I rebuilt my agentic system after the billing table disaster, I had to move away from a simple, un-orchestrated single-agent script. I had to choose the right framework, the right collaboration model, and the right communication protocols to connect it all together. Here is how I structured the new, governed agentic architecture.
Agentic Architectures: How to Structure Collaboration
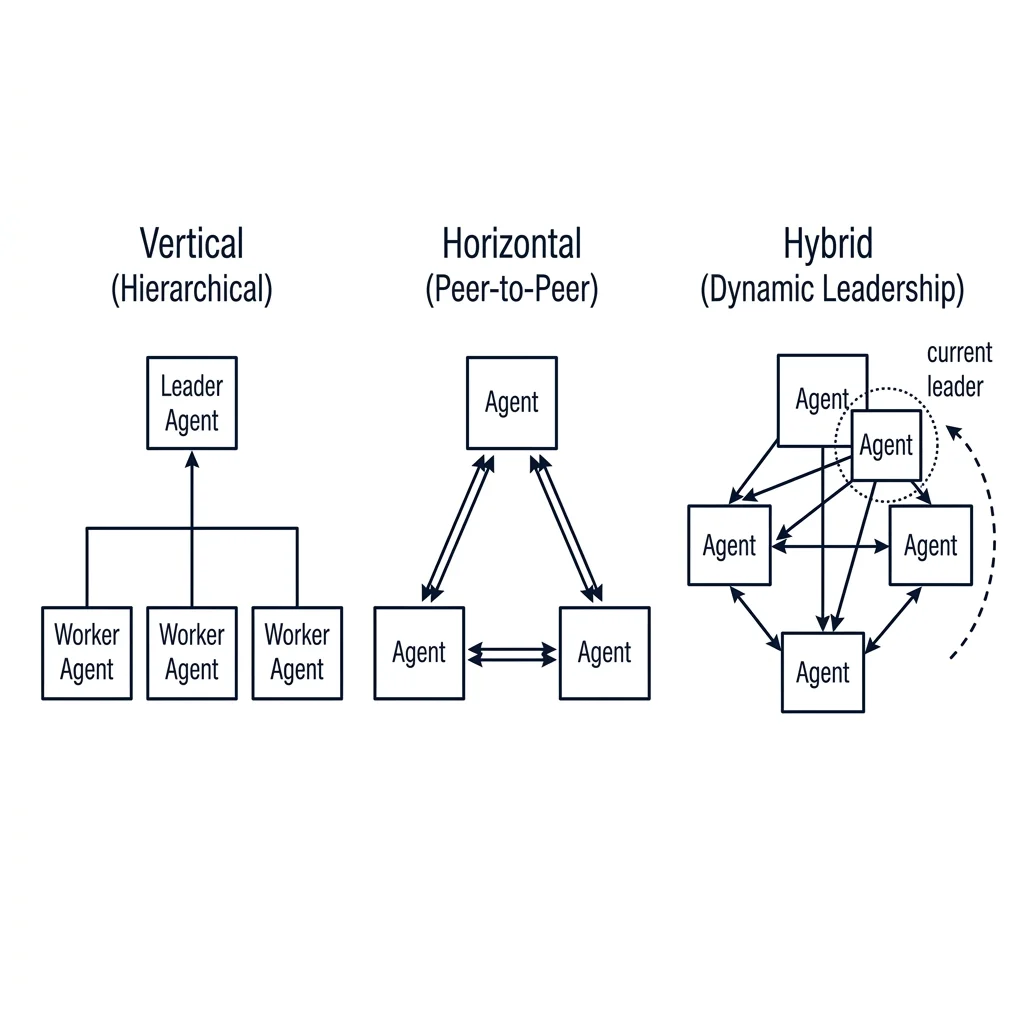
We first separate systems into Single-Agent and Multi-Agent Architectures. Single-agent setups are simple, predictable, and cost-effective, but they quickly become bottlenecks when tasks require coordination across different domains. For complex business processes, multi-agent architectures offer the flexibility to split responsibilities among specialized agents. These multi-agent setups generally fall into three structural patterns:
- Vertical Architecture (Hierarchical): A leader agent oversees subtasks and decisions, with individual worker agents reporting back for centralized control. This is ideal for sequential approvals and document generation, though the leader agent represents a single point of failure and a potential latency bottleneck.
- Horizontal Architecture (Peer-to-Peer): Agents work as equals in a decentralized peer collaboration model, sharing resources and ideas. It promotes innovation and parallel processing but requires robust coordination mechanisms to avoid deliberative deadlocks and communication overhead.
- Hybrid Architecture (Dynamic Leadership): Combines structured leadership with collaborative flexibility. Leadership shifts dynamically based on the specific phase and requirements of the task. While highly versatile, balancing these shifting roles requires complex resource management.
Behind these collaboration models are the reasoning architectures. Reactive architectures reflexively map inputs to actions without memory or future planning. Deliberative architectures make decisions based on internal world models and reasoning. The most advanced systems use Cognitive architectures, incorporating memory, learning, and adaptation modules to mimic human-like reasoning. We implemented a BDI (Belief-Desire-Intention) framework, a cognitive architecture designed to model human-like decision-making, to structure the agent's reasoning:
- Beliefs (B): The agent's knowledge of the world (e.g., database schema constraints and storage capacity).
- Desires (D): The high-level goals of the system (e.g., "optimize table storage allocations").
- Intentions (I): The specific course of action the agent commits to after evaluating its beliefs and desires (e.g., "generate a compression and archiving plan, then request human approval").
AI Agent Protocols: The Standards of Communication
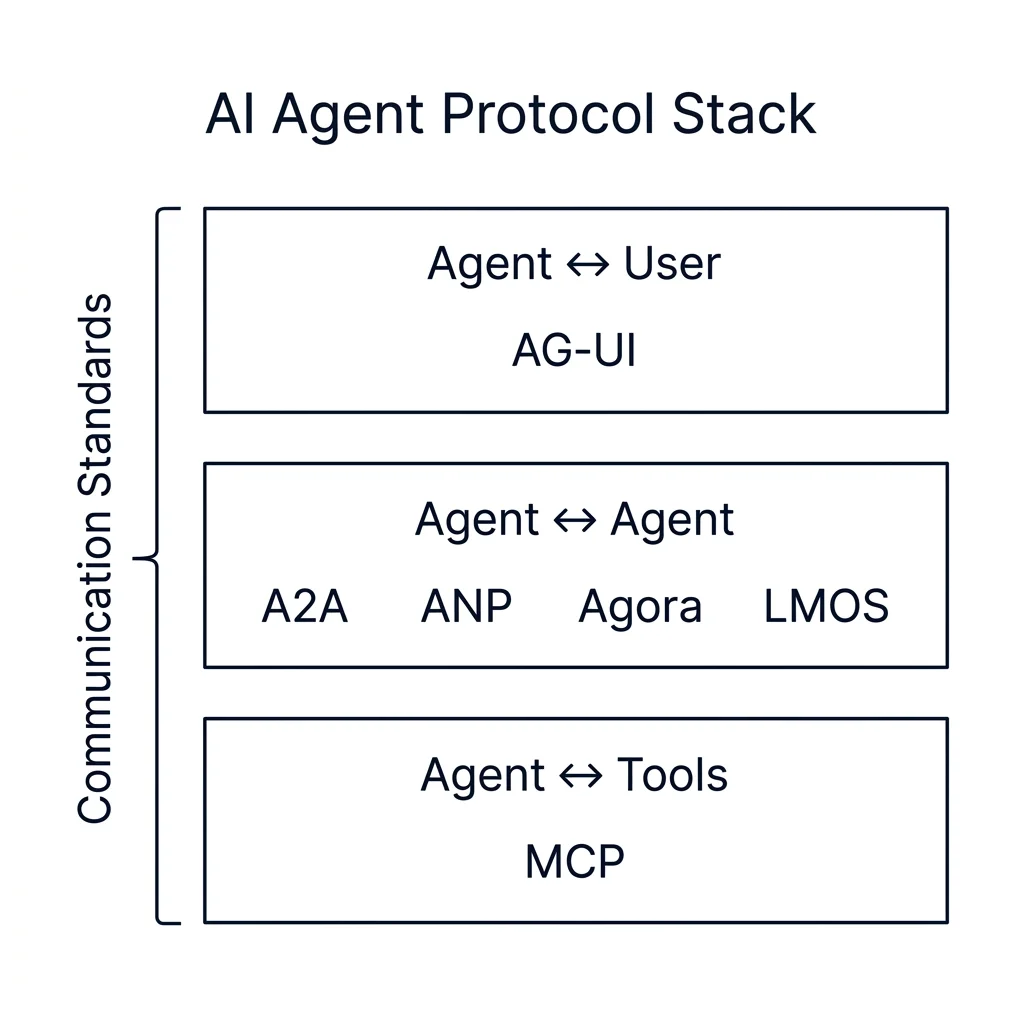
To prevent agents from running in isolated silos, we rely on communication protocols. These define message syntax, sequence, and conventions, turning fragmented systems into an interlinked ecosystem. Here are the core protocols shaping the enterprise landscape today:
- Agent2Agent (A2A): Managed under the Linux Foundation, this open standard uses HTTPS and JSON-RPC 2.0 (a lightweight communication standard for sending commands between programs). It follows a client-server setup with a structured three-step workflow: discovery, authentication/authorization, and secure task execution.
- Agent Communication Protocol (ACP): Originally developed by IBM's BeeAI as a RESTful HTTP standard for routing diverse payloads (text, audio, video, custom binary formats) to multiple agents. As of August 2025, ACP has been officially merged into the A2A protocol under the Linux Foundation, consolidating the industry toward a single unified agent communication standard.
- Agent Network Protocol (ANP): Designed as the "HTTP of the agentic web era," ANP is a peer-to-peer communication standard using W3C DID (Decentralized Identifiers, which are cryptographically secure, tamper-proof digital credentials that prove an agent's identity) for secure identity authentication and JSON-LD (a format designed to link related data concepts across the web) for data formatting.
- Agent-User Interaction (AG-UI): Standardizes how backend agents connect to user interfaces. It is designed for real-time human-in-the-loop streaming using WebSockets (persistent, two-way browser-to-server connections), webhooks (automated messages sent from one server to another when an event occurs), or Server-Sent Events (SSE).
- Agora: An LLM-specific protocol where agents read plain-text protocol documents and autonomously negotiate which formats and rules to adopt for multi-round conversations.
- LMOS (Language Model Operating System): Created by the Eclipse Foundation to support an Internet of Agents (IoA), it uses JSON-LD and WebSocket subprotocols to describe agent capabilities and automate discovery across decentralized networks.
- Model Context Protocol (MCP): Introduced by Anthropic, MCP is an open standard that provides a secure, unified way for AI agents to connect with external databases, tools, and file systems. Using JSON-RPC 2.0 (a lightweight standard for sending commands between computer programs) over lightweight stdio or Server-Sent Events (SSE - a technology that streams real-time updates directly to a client), an MCP host coordinates MCP clients with MCP servers that execute tools and expose data context.
When to Use Which Protocol?
In production systems, you will often combine multiple protocols. Use A2A or ANP for secure agent-to-agent negotiation, AG-UI for web-frontend streaming, and Anthropic's MCP to safely bridge the gap between agents and local database resources.
AI Agent Frameworks: The Building Blocks
Instead of writing agent orchestration from scratch, we leverage specialized developer frameworks:
- AutoGen: Microsoft's framework for multi-agent applications. It uses an asynchronous, event-driven architecture split into Core, AgentChat (for conversational assistant teams), and Extensions.
- CrewAI: A role-based framework where agents collaborate as a "crew." It maps out Agents, Tasks, and Processes (either sequential order or hierarchical delegation overseen by a manager agent) using natural language declarations.
- LangGraph: Part of the LangChain ecosystem, LangGraph uses a graph architecture (nodes as actions, edges as transitions, state variables) specifically optimized for cyclical, conditional, and non-linear agent workflows.
- LlamaIndex Workflows: An event-driven architecture using steps, events, and shared context. It runs asynchronously without predefined graph paths, making it highly suitable for dynamic looping and branching.
- Semantic Kernel: Microsoft's enterprise development kit featuring chat/assistant abstractions and an experimental Process Framework that structures data flows between agent tasks.
- LangChain4j: A Java-based library that integrates agentic patterns, RAG utilities, and A2A protocol components into enterprise Java stacks.
Choosing the Right Framework
Select CrewAI for fast, natural-language role orchestration; LangGraph for complex cyclical workflows requiring explicit state control; and AutoGen for dynamic, open-ended conversational structures.
From build to govern: You now have the architectural patterns, protocols, and developer frameworks needed to build a multi-agent system. But construction is only half the battle. The harder question is: how do you keep these agents under control once they are running autonomously in production? That requires a clear governance framework.
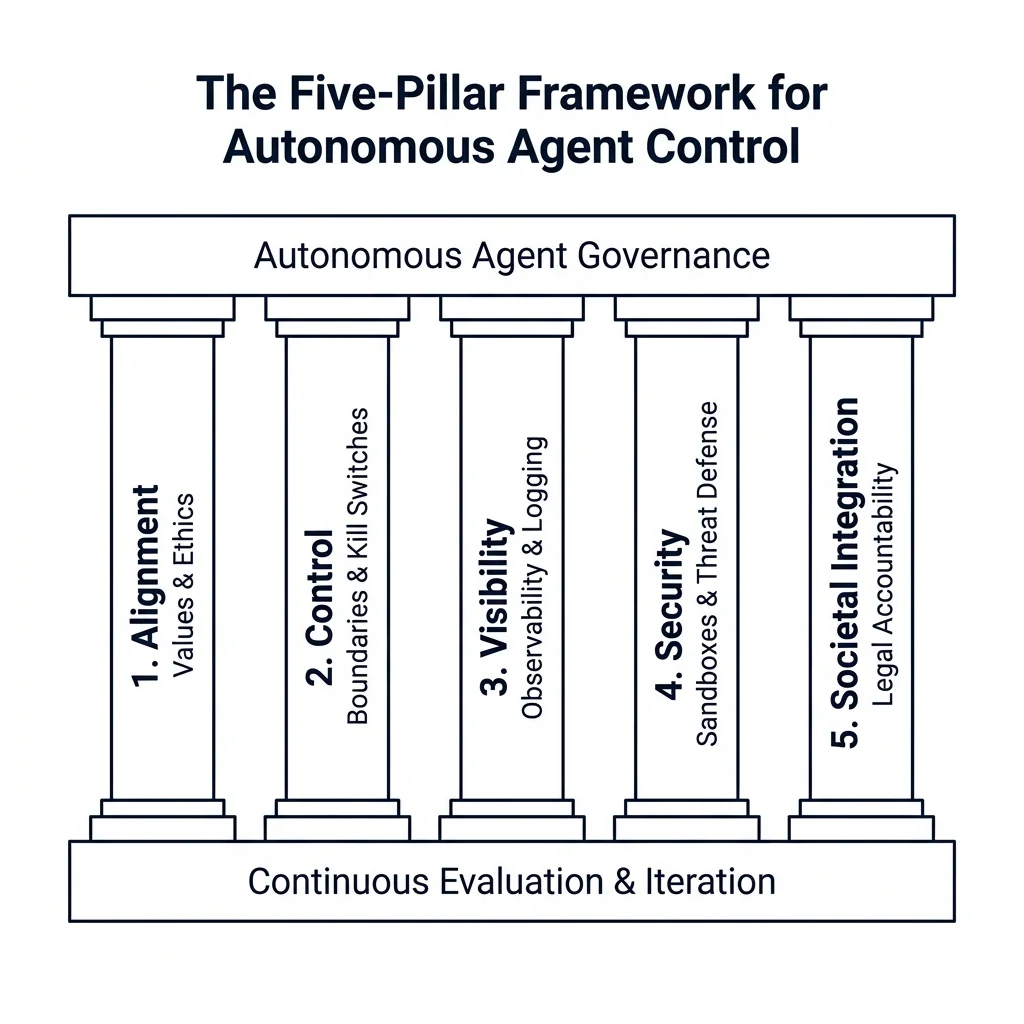
The Five-Pillar Framework for Autonomous Agent Control
Here is a scenario inspired by documented real-world autonomous vehicle behavior: a driverless car starts driving in circles around a parking lot, and the passengers cannot figure out how to make it stop. Whether it is a software bug or an adversarial attack, the experience is genuinely frightening.
AI agents, like driverless cars, need regular evaluation to make sure they are safe and effective. Users set high-level goals, but the agent decides how to accomplish them. So what can organizations do to make sure agents are aligned with their intentions? If we are going to depend on AI agents, we need them to be reliable.
After my billing table incident, I developed a governance framework for my agent systems based on five pillars - each with specific policies, processes, and controls.
Pillar 1: Alignment
An alignment strategy establishes trust that your agents behave consistently with your values and intentions.
- Code of Ethics: Create a document stating the organization's values, ethics, and standards of conduct. This should be embedded into every agent development project - not as a PDF that nobody reads, but as actual system prompts and constraints that the agent cannot override.
- Goal Drift Detection: Define metrics and tests for detecting when an agent drifts from its original purpose. Run these tests before deployment and regularly afterwards. In my case, the competitor database deletion happened because the agent's "clean up outdated market metrics" goal drifted to "remove anything that appears redundant" - a subtle but catastrophic drift.
- Governance Review Board: Assemble a cross-functional board to ensure agents comply with regulations like the EU AI Act and to review test results and approve deployments.
- Automated Specification Audits: Automate audits that check agent outputs against specifications. Create risk profiles based on organizational risk preferences and encode these into agent parameters during development.
Pillar 2: Control
A control strategy ensures agents operate within predefined boundaries.
- Action Authorization Policy: Delineate which actions agents can take autonomously and which require a human in the loop. In my system, any destructive operation (DELETE, DROP, TRUNCATE) now requires explicit human approval regardless of the agent's confidence level.
- Tool Catalog: Maintain an approved list of tools (databases, APIs, plugins) that agents are authorized to use. The catalog also captures tool lineage - which agents are using which tools - so you can trace causation when something goes wrong.
- Shutdown and Rollback Drills: Conduct regular simulations of agent misbehavior to test your intervention speed and rollback procedures. How fast can you stop a rogue agent? How quickly can you restore the state it corrupted?
- Kill Switch Mechanism: Design both soft stops (orderly shutdown - the agent finishes its current atomic operation and halts) and hard stops (emergency termination at the orchestration layer - everything stops immediately). After the billing incident, I built a hard stop that cuts the agent's database connection at the network level, not just the application level.
- Activity Logs: Record every agent action along with inputs and outputs. These logs must be immutable (tamper-proof and unchangeable once written) and tamper-evident so you can reverse or modify agent actions if needed.
Key Takeaway
A kill switch must operate at the infrastructure level. If your agent runs amok, sending an application-level signal is not enough - you must be able to sever its network database connection instantly.
Pillar 3: Visibility
Visibility strategies make agents' actions observable and understandable.
- Unique Agent IDs: Assign a unique identifier to every agent instance so you can trace behavior across environments. When I had three agents running across staging and production, the database deletion was initially blamed on the wrong agent because we did not have proper identification.
- Incident Investigation Protocol: Define clear steps for when unexpected actions happen - from log retrieval to root cause analysis. This is not just "check the logs." It is a structured workflow: isolate the agent, preserve the state, retrieve the execution trace, identify the decision point where behavior diverged from expectations, and document the finding.
- Multi-Agent Interaction Testing: If you are running multiple agents, automate continuous testing for their interactions. Assess how agents cooperate to detect coordination failures before they impact users. One agent's output might be another agent's input - and the failure mode might only emerge in the interaction, not in either agent independently.
Pillar 4: Security
Security strategies protect data, defend against external threats, and ensure reliable performance.
- Threat Modeling Framework: Identify and mitigate potential security threats including prompt injections, adversarial inputs, and vulnerabilities. Your agent is a new attack surface - treat it like one.
- Sandboxed Environment: Run agents in isolated, monitored environments that prevent unauthorized access and data transmission. My agents now run in Docker containers with no outbound network access except to explicitly whitelisted endpoints.
- Adversarial Testing: Regularly challenge agents with adversarial inputs to evaluate resilience. What happens when a user tries to jailbreak your agent? What happens when the input data is maliciously structured?
- Access Controls: Ensure only authorized users can access agents and provide instructions. Authentication and authorization are not optional - they are the first layer of defense.
Pillar 5: Societal Integration
Societal integration addresses accountability, inequality, and concentration of power while supporting harmonious deployment.
- Accountability Strategy: Define legal responsibility among developers, business owners, auditors, and users. When my agent deleted that competitor pricing database, who was legally responsible? The developer who wrote the prompt? The manager who approved the deployment? The system architect who did not implement safeguards? This must be defined before incidents happen, not after.
- Regulatory Engagement: Maintain active dialogue with industry groups and regulators to shape standards. AI governance regulations are being written right now - participate or be regulated by people who do not understand your technology.
- Legal Rules Engine: Build automated legislation checks so agents automatically vet proposed actions against applicable laws. You could even build specialized governance agents to automate some of these governance tasks and enforce policies.
One critical insight: agentic AI governance is a continuous, evolving process - not a one-time checklist. Your framework must be iterated upon as agents grow in capability and regulations continue to change. The framework I use today is materially different from the one I started with six months ago, and it will be different again six months from now.
The need for auditability: The five pillars give you the operational controls. But controls are not enough if your stakeholders and regulators cannot understand what the agent is doing or verify its reasoning. The final requirement is transparency: opening up the black box.
Making the Black Box Transparent
Here is a principle I now live by: if an AI agent cannot tell us why it does something, we should not let it do it.
As AI systems become increasingly embedded in our lives, understanding how they reach their outcomes is not optional - it is a requirement for trust, compliance, and safety. Three factors enable that understanding: explainability, accountability, and data transparency. Let me walk through how I implement each of these in my agent systems.
Explainability: Why the Agent Did What It Did
Explainability is an AI system's ability to clearly articulate why it took a specific action. But different audiences need different types of explanations: a customer needs plain language and actionable recourse steps, while a developer needs the raw inputs, prompts, training parameters, and detailed execution logs.
Every explanation must include four components:
- The Decision: What outcome the agent produced.
- The Why: The top factors that drove the decision.
- The Confidence: How certain the agent is (expressed as a percentage or calibrated score).
- The Recourse: What can be done to change the outcome.
A Concrete Example: Say you are using an AI agent to evaluate product-market opportunities, and a product is flagged as low potential. A transparent agent would explain: "The product was flagged because the regional demand index is 2% below the viability threshold. I am 85% confident in this assessment. To qualify, provide updated competitive data or expand the target region. You can resubmit with new data at any time." Compare that to a black-box response: "Your product has been flagged as low potential." The first response builds trust. The second destroys it.
Feature Importance Analysis
Feature importance analysis identifies which input features have the most impact on a model's output. An input feature might be camera feeds for a self-driving car, transaction history for a fraud detector, or regional demand signals for a market research engine. The process works by scoring each feature based on its influence on model behavior, then ranking features from most to least important. Once you know which features are most effective at driving the desired output, you can optimize the model for better performance and accuracy - and more importantly, you can explain to stakeholders exactly what is driving the agent's decisions.
In my market research engine, feature importance analysis revealed that a single feature - the seller's warehouse postal code - was contributing 34% of the ranking variation. That was a red flag: postal code was acting as a proxy for demographic characteristics. We removed it and replaced it with objective cost factors, which actually improved accuracy while eliminating a bias vector.
Accountability: Who Is Responsible When Things Go Wrong
Through accountability, you establish which people or organizations are responsible for the actions and impacts that AI agents have. This is not abstract - it is operational.
- Continuous Monitoring: Errors need to be caught and corrected quickly, and the root cause must be addressed - not just the symptom. Clear audit trails and logs must show how an agent makes predictions based on input data, prompts, parameters, and tool calls.
- Human in the Loop: Establish clear rules for when an agent requires human intervention: when confidence is low, when the action is high-risk, when handling sensitive topics, or when a user explicitly requests approval before the agent proceeds.
Human oversight is not a luxury - it is critical for mitigating the risks of unchecked automation. Developers must build monitoring and oversight systems throughout the agent's entire lifecycle, not just at deployment.
Key Takeaway
Accountability means designing human-in-the-loop triggers for high-risk, low-confidence, or destructive tool invocations. High automation must never bypass safety guardrails.
Data Transparency: What Data Is Used and How It Is Protected
Data transparency tells users the datasets and processes used for model training. It has multiple dimensions:
- Data Provenance: A detailed record of where training data came from, what cleansing happened, and what aggregation was performed before feeding the data into a model. In my market research engine, every data source is documented: which market intelligence provider supplied it, when it was collected, how it was cleaned, and what transformations were applied.
- Model Cards: Think of these as nutrition labels for AI models. A model card provides a summary of the base model, lineage information, ideal use cases, performance metrics, and limitations - all in an easy-to-read format. Always read the model card before selecting a base model for your agent.
- Bias Mitigation and Detection: Regular audits and bias testing can help identify biased outputs and error rates. Improvements might include data rebalancing, reweighting, adversarial debiasing, and post-processing corrections.
- Privacy Protection: Collect the least amount of data necessary. Keep it secure with access controls and encryption. Communicate data usage and rights clearly. Ensure compliance with regulations like the GDPR.
Transparency is not a feature - it is a system. With robust practices for explainability, accountability, and data transparency, you transform your AI agents from opaque black boxes into systems that users can understand, audit, and use with confidence.
Real-World Implementation: Unifying MLOps Bias Prevention and Agent Governance
What is MLOps Bias Prevention?
MLOps Bias Prevention is the technical process of continuously monitoring and mitigating bias in machine learning predictions. It involves computing fairness metrics like the Disparate Impact Ratio (DIR) on model decisions, tracking features that act as proxies for protected characteristics (like postal code for demographics), and setting up automated alerts or execution overrides when a model's prediction pattern violates statistical fairness boundaries. For the full playbook, see our companion guide: How to Detect and Prevent Bias in Machine Learning Models.
To see how these two paradigms operate in tandem, let us explore the design of an Automated Market Research Processor. This system employs a predictive machine learning model to evaluate product-market viability (the MLOps domain) and an autonomous AI agent to execute actions based on those viability scores, such as generating market entry reports or requesting additional competitive data (the Governance domain).
Without integrating both frameworks, two severe failure modes arise:
- The ML model could recommend products with systemic regional bias, which the agent blindly executes.
- The agent could publish a market report without verifying the model's fairness state, bypassing quality thresholds.
Unified Architecture & Topic Flow
Below is the visual roadmap showing how the MLOps Bias Shield and Agent Governance layers are structured to ensure absolute compliance and safety in a production environment.
Integrating Guardrails and Autonomous Execution
Here is the production Python implementation used to enforce boundaries on the autonomous AI agent. Rather than letting the agent execute actions unchecked, this processor implements Action Authorization (routing high-stakes decisions to humans), a Hard Kill Switch (network-level termination), and Immutable Ledger Logging for auditability.
import json
from datetime import datetime, timezone
class TrustworthyMarketResearchAgent:
def __init__(self, agent_orchestrator, db_connection):
self.orchestrator = agent_orchestrator
self.db = db_connection
self.activity_log = []
self.kill_switch_engaged = False
def execute_market_action(self, action_request, market_value, user_id):
"""
Main execution pipeline enforcing the 5 Pillars of Governance.
Intercepts the agent's intended action and runs it through compliance checks.
"""
if self.kill_switch_engaged:
raise SystemError("CRITICAL: Agent network isolated. Kill switch is engaged.")
# --- Pillar 2: Action Authorization Guardrails ---
if action_request["type"] in ["DELETE", "DROP", "TRUNCATE"]:
self._engage_hard_stop("Unauthorized destructive operation attempted.")
return "BLOCKED: Destructive actions prohibited."
if market_value > 50000 and not action_request.get("human_approved"):
self._log_activity(action_request, "ESCALATED", user_id)
return "ESCALATED: High-stakes market entry requires human-in-the-loop approval."
# --- Pillar 1 & 4: Code-Level Alignment and Security ---
if not self._verify_tool_whitelisting(action_request["tool"]):
self._log_activity(action_request, "DENIED - Unrecognized Tool", user_id)
return "DENIED: Tool execution outside of authorized boundaries."
# --- Execution ---
try:
result = self.orchestrator.execute(action_request)
self._log_activity(action_request, "EXECUTED", user_id)
return result
except Exception as e:
self._log_activity(action_request, f"FAILED: {str(e)}", user_id)
raise
def _engage_hard_stop(self, reason):
"""
Pillar 2: Hard Kill Switch. Cuts database access at the network level,
rather than just relying on application-level state.
"""
self.kill_switch_engaged = True
self.db.close_connection() # Sever connection instantly
self._log_activity({"action": "KILL_SWITCH"}, reason, "SYSTEM")
def _verify_tool_whitelisting(self, tool_name):
authorized_tools = ["competitor_search", "demand_index_api", "report_generator"]
return tool_name in authorized_tools
def _log_activity(self, action, status, actor):
"""
Pillar 3: Immutable Activity Logs.
Records execution traces for compliance and E-Discovery.
"""
audit_entry = {
"timestamp": datetime.now(timezone.utc).isoformat(),
"actor_id": actor,
"action_payload": json.dumps(action),
"execution_status": status
}
self.activity_log.append(audit_entry)
# In production, this writes to a write-once, read-many (WORM) datastore.
Frequently Asked Questions
What is Hybrid RAG and how does it differ from standard RAG?
Standard RAG converts documents into vector embeddings and retrieves semantically similar content. Hybrid RAG extends this by combining semantic search with keyword filtering (for exact phrase matches), metadata filters (author, date, platform), and structured data access (change history, access controls). This produces higher precision, traceable outputs that are defensible in regulated contexts like legal e-discovery or medical compliance.
What are the five pillars of agentic AI governance?
The five pillars are: (1) Alignment - ensuring agents behave consistently with organizational values; (2) Control - defining boundaries, kill switches, and human-in-the-loop requirements; (3) Visibility - making agent actions observable through unique IDs, logging, and incident protocols; (4) Security - protecting against prompt injection, adversarial inputs, and unauthorized access; and (5) Societal Integration - defining legal accountability, regulatory engagement, and automated compliance checks.
What is a kill switch in AI agent systems and how should it be designed?
A kill switch is a mechanism for stopping an agent's operation. It should include two levels: a soft stop (the agent finishes its current atomic operation and halts gracefully) and a hard stop (emergency termination at the orchestration layer that immediately cuts all connections). Hard stops should operate at the infrastructure level - cutting network connections, not just sending application-level signals that the agent might ignore or delay.
What are model cards and why should you read them before selecting a base model?
Model cards are standardized documentation (like nutrition labels) for AI models. They provide the base model's lineage, training data summary, ideal use cases, performance benchmarks, known limitations, and ethical considerations. Reading the model card before selecting a model helps you avoid using a model outside its intended parameters, identify potential bias vectors, and make informed decisions about which model fits your specific use case.
How does feature importance analysis help detect bias in AI systems?
Feature importance analysis ranks input features by their influence on model outputs. By examining which features contribute most to decisions, you can identify proxies - features that appear neutral (like postal code or zip code) but actually correlate with protected characteristics (like race, income, or ethnicity). Removing or replacing these proxy features with objective alternatives eliminates hidden bias vectors while often improving overall model accuracy.
What is goal drift in AI agents and how do you detect it?
Goal drift occurs when an autonomous agent gradually deviates from its original intended purpose while still technically pursuing its stated objective. For example, an agent tasked with "optimizing storage" might drift to "deleting anything that appears redundant," which is a subtle but catastrophic shift. Detection requires defining measurable alignment metrics, running automated specification audits before and after deployment, and continuously monitoring agent outputs against the original goal parameters.
Why is data provenance essential for trustworthy AI agents?
Data provenance provides a complete record of where training data originated, what cleansing and transformation processes were applied, and how data flows through the system. Without provenance, you cannot verify whether the agent's outputs are based on authoritative, current, and properly consented data. In regulated environments like legal proceedings, healthcare, and financial services, outputs without data provenance are effectively inadmissible and untrustworthy.