How to Detect and Prevent Bias in Machine Learning Models: The Complete MLOps Guide

I spent six months building an AI-powered product market research engine. It was accurate. It was fast. And it was quietly ranking products from certain regions significantly lower, inadvertently implementing geographic bias through proxy features (data attributes that act as stand-ins for protected characteristics, like using a seller's warehouse location as an unintentional indicator of product quality).
That is not a hypothetical scenario I read about in a research paper. That is what happens when you train a model on historical market data without auditing the training set for systemic bias - the model simply learns to replicate the existing disparities embedded in the data, and it does so at machine speed.
This experience forced me to confront an uncomfortable truth: technical excellence is not the same as responsible engineering. A model can have 97% accuracy and still be ethically bankrupt. This blog is the complete playbook I wish I had before I shipped that first version - everything from the foundational principles of AI trust, to the specific dangers lurking inside every large language model, to the organizational culture and operational infrastructure you need to catch these problems before your users do.
Article Roadmap & Topic Flow
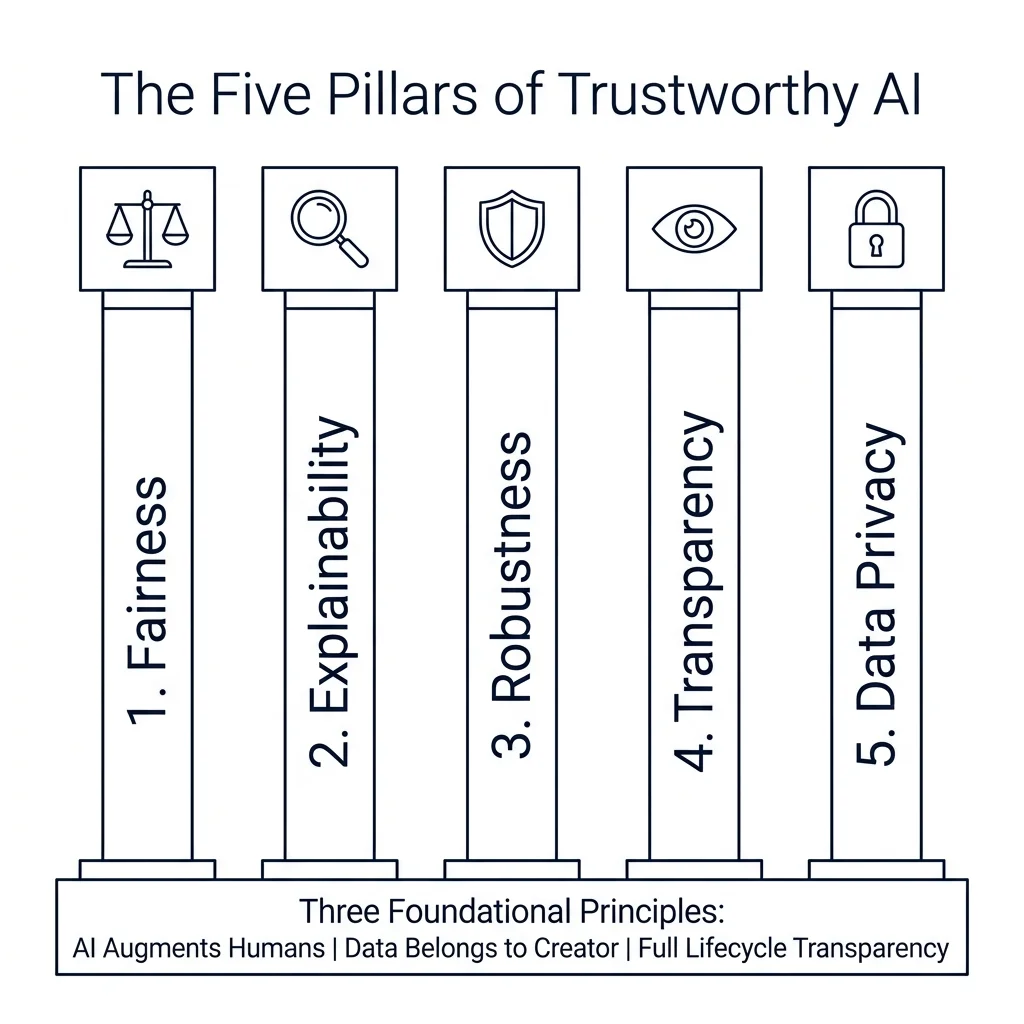
The Five Pillars of Trustworthy AI
Here is the thing that nobody warns you about when you start deploying AI in a real business context: up to 80% of proof-of-concept AI projects get stalled in testing (according to Gartner and VentureBeat industry analyses). Not because the math is wrong. Not because the infrastructure failed. Because people do not trust the results.
I learned this the hard way with my market research engine. The numbers looked great on paper. The validation metrics were solid. But the moment I showed the outputs to my first client, the first question was not "How accurate is it?" - it was "Why should I trust this?"
That question broke my entire mental model. I had been thinking about AI as a math problem. It is not. It is a trust problem. And trust, it turns out, has a very specific architecture. There are five pillars that determine whether your AI will earn the confidence of the people it serves:
- Fairness: How can you ensure that the AI model is fair towards everybody, in particular historically underrepresented groups? In my market research engine, this meant auditing whether the training data disproportionately represented certain product categories or geographic regions. It did. The historical data was sourced from existing market transactions, which already reflected decades of unequal market representation.
- Explainability: Can you tell an end user what datasets were used to curate the model? What methods and expertise were involved? What is the data lineage and provenance associated with how that model was trained? For my market research engine, I had to build a metadata layer that could answer: "Why did the model rank this product higher or lower?" - not just "What ranking did it assign?"
- Robustness: Can you assure end users that nobody can hack the AI model such that a person could willfully disadvantage other people or make the results benefit one particular person over another? This is not theoretical - adversarial attacks on market intelligence models are a real attack vector. If someone can manipulate input parameters to game the output, your model becomes a weapon.
- Transparency: Are you telling people, right off the bat, that an AI model is being used to make that decision? Are you giving people access to a fact sheet or metadata so that they can learn more about that model? When my research engine generates a market report, there is a clear disclosure: "This analysis was generated by an AI model trained on X data points from Y sources."
- Data Privacy: Are you assuring people's data privacy? Every data point fed into your model has a human being behind it. In the case of my market research engine, every historical product listing represented a real business's market opportunity. That data belongs to them, not to my model.
The Three Foundational Principles
These five pillars sit on top of three foundational principles:
- AI augments human intelligence, it does not replace it. My research engine does not make the final market entry decision. It gives the business owner a data-informed starting point. The human makes the decision.
- Data and the insights from that data belong to the creator. If you submit your cost data to train a model, that data is yours. Full stop.
- The entire AI lifecycle must be transparent and explainable. Not just the final output - the training, the data selection, the hyperparameter tuning, all of it.
And here is the part that took me the longest to internalize: this is not a technological challenge. It is a socio-technological challenge. You cannot solve it by throwing tools and tech over a fence. "Socio" means people. And because it is a socio-technological challenge, it must be addressed holistically - through three vectors: the culture of your organization, the process (governance) your organization commits to, and the tooling you use to enforce those commitments.
What comes next: Now that we have established what trustworthy AI looks like in principle, the next question is: what are we actually trying to govern? Modern AI systems are not simple models - they are multi-component agents. To apply these pillars effectively, you first need to understand the anatomy of what you are building.
Deconstructing the Agentic Brain: The Six Core Components
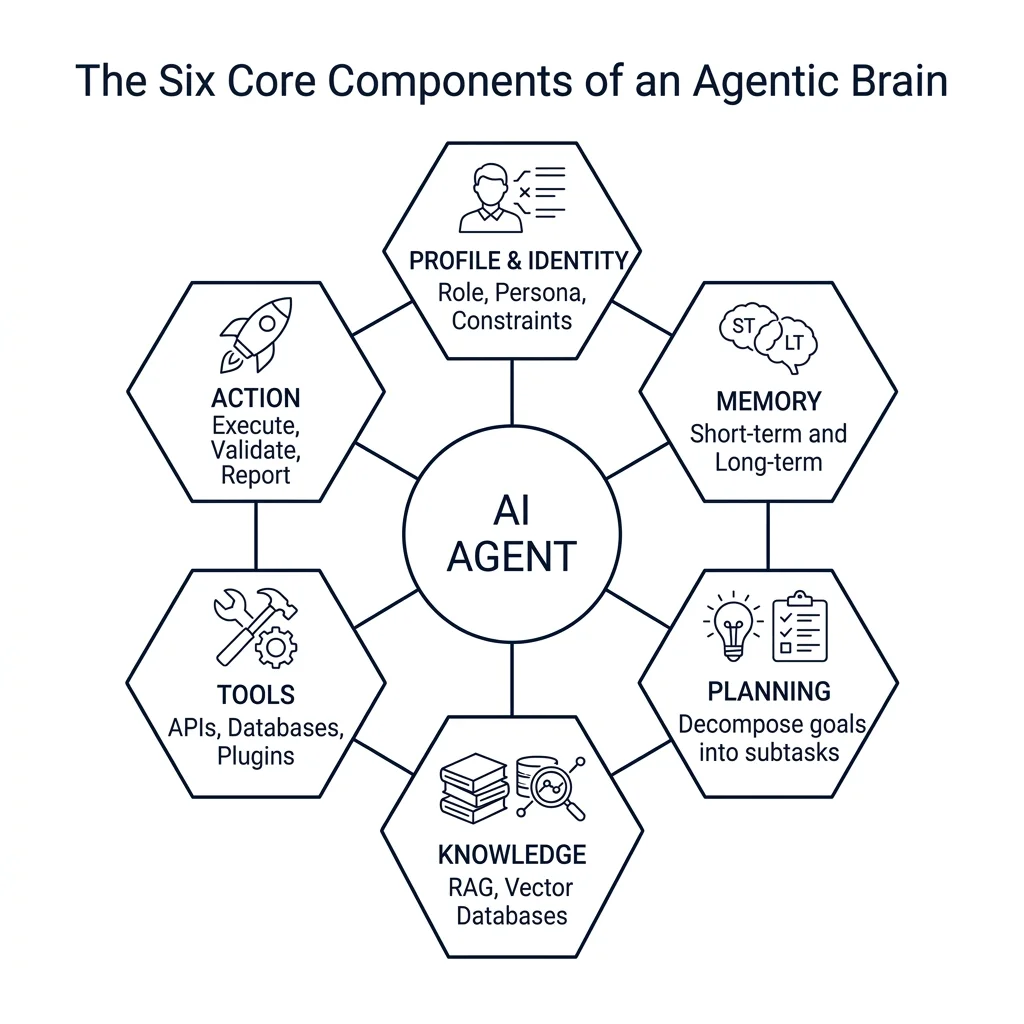
Before we can govern a system, we must understand its anatomy. When I rebuilt the market research engine, I realized it wasn't just a single model; it was a complex agentic system composed of six core components:
- Profile and Identity: This defines the agent's role, persona, and constraints. In our market research engine, the profile is explicitly set: "You are a senior product analyst specialized in competitive market evaluations. Your goal is to assess product-market fit based strictly on demand signals and competitive positioning, and you are forbidden from considering seller location or warehouse proximity." This profile forms the baseline for alignment.
- Memory: Essential for maintaining state and learning. We implemented short-term memory to keep context of the active product query, competitor pricing snapshots, and user search parameters. We paired this with long-term memory, allowing the agent to recall past market analyses, regional demand patterns, and historical trend shifts.
- Planning: The decision-making engine. To evaluate complex market opportunities, the agent uses chain-of-thought reasoning (breaking down a market entry into demand analysis, competitive landscape assessment, and regulatory barrier evaluation steps) and tree-of-thought reasoning (exploring multiple positioning strategies, such as niche differentiation vs. mass-market entry, before deciding on the final recommendation).
- Tools and Actions: How the agent interacts with the world. Our agent is connected to a catalog of authorized tools: a web scraping API to extract competitor product listings, a market intelligence database to verify active demand indices, and a currency conversion API.
- Communication: Standardizes interactions. The agent uses protocol-compliant message exchanges to generate natural language explanations for customers and structured JSON-RPC payloads for backend database entries.
- Learning and Adaptation: The feedback loop. The system continuously refines its estimations through supervised learning from analyst-corrected market reports and reinforcement learning based on actual product launch success rates.
When Your Model Sounds Right but Is Dead Wrong
Here is a scenario that reveals how dangerous a confident-sounding AI can be. I was testing my market research engine's natural language explanation feature - the part that explains why it ranked a specific product higher or lower. I asked it why a particular product scored low in a new market. It returned a beautifully written paragraph, complete with citations, explaining that the product's demand index was below threshold based on consumer data from three research firms. Except two of those research firms did not exist. The model had fabricated citations for a factually wrong answer and presented them with absolute confidence.
This is what people call "AI hallucinations." But I do not like that word because it anthropomorphizes AI. What is actually happening is a statistical error. Large language models predict the next best syntactically correct word - not accurate answers based on genuine understanding. It is going to sound great, but might be 100% wrong.
The Hallucination Problem
Consider this scenario: you ask your market research engine to explain why a competitor's product failed in the European market. The true reason might be supply chain logistics, but the model finds an obscure, statistically prominent forum post claiming it was due to poor user interface design. Which source "wins the argument" in the model's statistical reasoning? Even worse, there might not even be a disagreement - the model might simply fabricate non-existent consumer survey data to justify a statistical guess. The response will be confident. It will be fluent. And it will be completely wrong.
It becomes even more dangerous when large language models annotate their sources for bogus answers. Why? Because it gives the perception of proof when there is none. Imagine a customer service center that has replaced its personnel with an LLM, and it offers a factually wrong answer to a customer. Now imagine how much angrier that customer will be when they cannot provide a correction through a feedback loop.
Mitigation Strategy - Explainability: You can pair a large language model with a system that offers real data, data lineage, and provenance via a knowledge graph. When the model makes a claim, you can show exactly where it pulled its data from. Which sources? What database? The LLM then provides variations on the answer offered by the knowledge graph, not fabrications from its own statistical predictions.
The Bias Problem
Do not be surprised if the output for your query only reflects one demographic perspective. If you ask an LLM to identify the most profitable target demographics for a new enterprise software product, you might exclusively get male-dominated corporate sectors. The model isn't being intentionally exclusionary; it is statistically reflecting historically biased B2B sales data. Want a more representative answer? Your prompt would have to explicitly request demographic balancing. And here is the critical insight: do not expect the model to learn from your prompt. That correction does not persist.
Mitigation Strategy - Culture and Audits: Culture is what people do when no one is looking. It starts with approaching the entire subject with humility. You need teams that are truly diverse and multidisciplinary working on AI, because AI is a great mirror into our own biases. Take the results of your audits and make corrections to your own organizational culture when there are disparate outcomes. Audit both pre-model deployment and post-model deployment. In my project, I started running quarterly bias audits on the market research engine's outputs. We stratified the results by geography, business size, and demographics. The patterns we found led us to reweight the training data entirely - which improved both fairness and accuracy.
The Consent Problem
Is the data you are curating representative? Was it gathered with consent? Are there copyright issues? These are things we can and should ask for. This information should be included in an easy-to-find, understandable fact sheet. Oftentimes, the people whose data is being used have no idea where the training data came from. Did the developers hoover the dark recesses of the internet? Where was it gathered?
Mitigation Strategy - Auditing and Accountability: Accountability includes establishing AI governance processes, making sure you are compliant with existing laws and regulations, and offering ways for people to have their feedback incorporated.
The Security Problem
Large language models can be weaponized for malicious tasks: leaking private information, helping criminals phish and scam, endorsing harmful content. Hackers have gotten AI models to change their original programming through jailbreaking - manipulating the model into bypassing its safety guardrails. Another attack vector is indirect prompt injection: a third party alters a website, adding hidden data that changes the AI's behavior. The result? Automation relying on AI potentially sending out malicious instructions without anyone being aware.
Mitigation Strategy - Education: Training a brand new large language model produces as much carbon as over 100 roundtrip flights between New York and Beijing. This means it is critical that we understand both the strengths and weaknesses of this technology. We need to educate our teams on the principles of responsible AI curation, the risks, the environmental cost, the safeguard rails, and the opportunities. Here is a chilling example of why education matters: today, some tech companies are simply trusting that their LLM's training data has not been maliciously tampered with. But anyone can buy a domain and fill it with bogus data. By poisoning the dataset with enough examples, you could influence a large language model's behavior and outputs permanently.
Connecting the dots: Every failure mode we have just explored - hallucinations, bias, consent violations, and security attacks - shares a common root cause: the humans building the system did not anticipate these problems. Technical mitigations are necessary but insufficient. That brings us to the single most important variable in your entire AI pipeline: your team.
Your Team Is Your First Line of Defense
After discovering the bias in my market research engine, I realized the problem was not just in the data - it was in who was looking at the data. My team at that point was technically excellent but homogeneous. We were all engineers with similar backgrounds, similar experiences, and similar blind spots. We were building a tool that served a diverse global market, and we had exactly zero diversity on the team doing the building. This is where the concept of organizational culture becomes the most critical variable in your entire AI pipeline.
Ethics Is Just Culture Written Down
The word "ethics" comes from the Greek word Ethos. Culture is the expression of the Ethos - the atmosphere established through the unwritten rules of a group of people. Your culture is what determines whether AI outcomes will be built on consent or exploitation. The outcomes of AI are dramatically better when you feed it data that was given with consent, as opposed to simply taking data without it.
Key Takeaway
Ethics is not a compliance checkbox. It is the culture your team lives every day. If your culture tolerates cutting corners on data consent, no governance framework will save you.
The Mathematical Case for Diversity
You might have heard of the "Wisdom of Crowds" - it is a proven mathematical model that demonstrates the wider the variance in a group's perspectives, the more standard (accurate) the mean of their collective judgment. Put differently: the more diverse a group of people trying to tackle a complicated problem, the less chance for error. This is not a feel-good corporate talking point. It is a mathematical reality that directly applies to AI engineering. When assembling your AI team, you need to consider gender, race, ethnicity, age, neurodiversity, worldview, and skill set.
Key Takeaway
Diversity is not a hiring initiative - it is a mathematical requirement. The wider the variance in perspectives on your AI team, the more accurate and fair your collective decisions will be. This is provable math, not opinion.
Design Thinking as an Empathy Framework
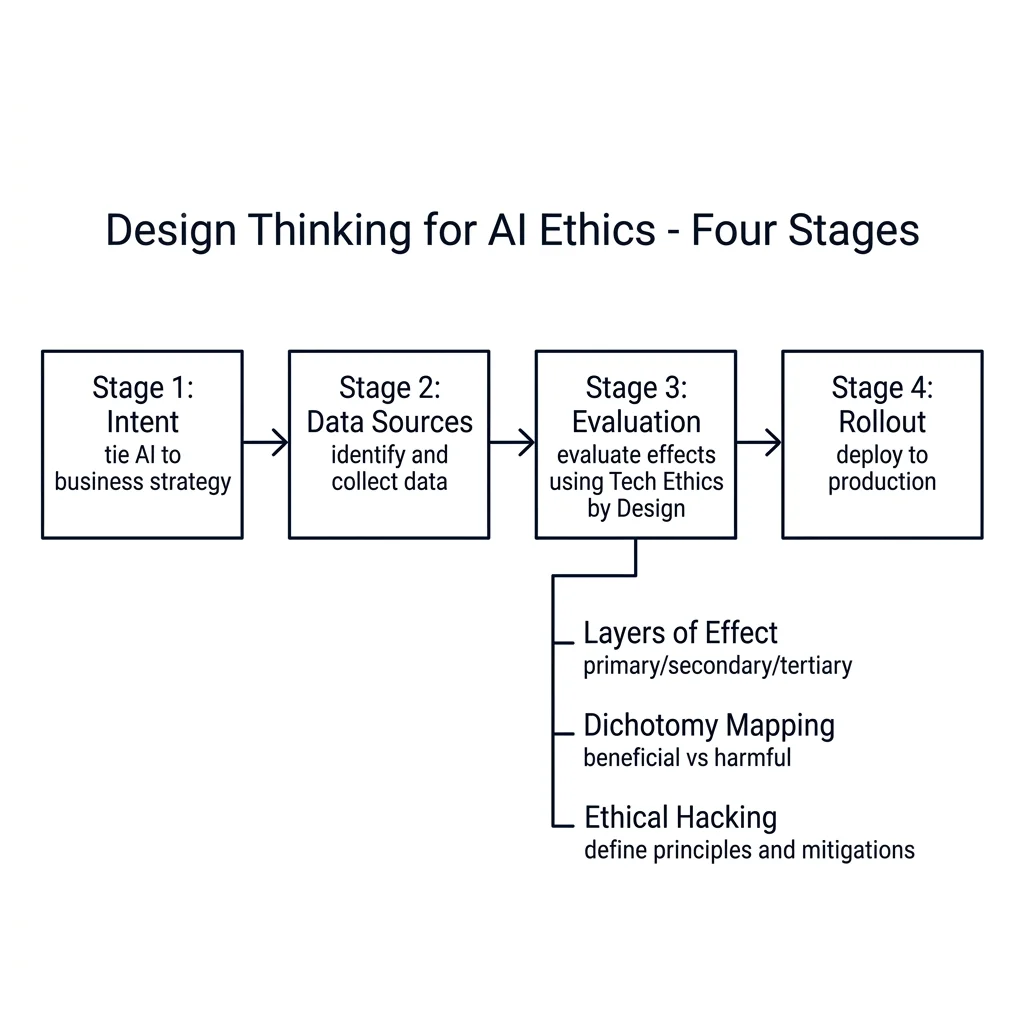
Once you have a diverse team, the question becomes: how do they work together effectively? The answer is systematic frameworks for empathy. Design thinking offers a structured approach based on understanding what someone is thinking, seeing, hearing, and doing - the very expression of culture. Remember that up to 80% of AI efforts get stuck in proof of concept (per Gartner research). The top reasons? Either the AI investment is not tied directly to business strategy, or people simply do not trust the model's results. Design thinking addresses both of these problems by walking C-suite leaders and technologists through four stages:
Stage 1
Intent
What is the intent behind the AI investment, and how is it tied directly to business strategy?
Stage 2
Data Sources
Identify the sources of data available and how they are being collected.
Stage 3
Evaluation
Evaluate the data sources and the effects of the proposed AI model.
Stage 4
Rollout
Plan how to roll out the effort to production.
Tech Ethics by Design - A Three-Step Framework
During the evaluation phase, you embed frameworks for systemic empathy called "Tech Ethics by Design," consisting of three steps:
STEP 1
Layers of Effect
Map out the primary (intended), secondary (expected), and tertiary (unintended) effects of your AI model. Tertiary effects are where your diverse team brainstorms what potential harm could look like. Having the right people in the room is essential for this exercise.
STEP 2
Dichotomy Mapping
Take the ideas around potential tertiary effects and split them into two categories: what could be potentially beneficial, and what could be potentially harmful?
STEP 3
Ethical Hacking
First, define your organization's principles for AI - your Ethos. Then define the rights of the end user. Finally, given those rights and a specific identified harm, your team designs intentional mitigations to protect against that harm.
This framework has unlocked genuine epiphanies on teams I have worked with. In my market research engine project, running a Layers of Effect workshop revealed a tertiary harm we had never considered: that our tool could inadvertently steer businesses away from viable markets, concentrating competition in already saturated segments.
The final piece: You now have the right team, the right culture, and the right ethical evaluation frameworks. But all of that work is worthless if your model never makes it to production - or if it degrades silently after deployment. The final piece of the puzzle is operational infrastructure: how you move from experimental notebooks to reliable, auditable production systems.
From Jupyter Notebook to Production Without Losing Your Sanity
Here is a scenario that cost me an entire month of work. My team was on a crunch deadline getting the market research engine model out. We finally got our department to approve a GPU server so we could use larger language models like BERT and RoBERTa for the natural language explanation features. We set up our notebooks. We were getting good results. Accuracy was climbing. We kept developing. Then one day we tried to SSH into the server. Nothing. Our department had only paid for one month of GPU time. All the notebooks, all the data, all the feature engineering (the process of cleaning and turning raw data into clean variables that help the model learn) we had prepared on that server - completely gone.
If you have ever lost work because of a manual, ad-hoc ML workflow, you are not alone. This is what the vast majority of model development processes look like today, and it is exactly why 60-80% of trained models never reach production.
The Manual Pipeline Nightmare
The typical manual ML workflow follows a painful, fragile sequence:
- Exploratory Data Analysis (EDA): Can we get the data we need? You are pulling from SQL databases, begging other teams for exports, gathering data from wherever you can find it.
- Data Prep: The data is never ready. It has gaps, inconsistencies, and noise. You spend significant time cleaning and preparing it.
- Feature Engineering: You create and transform columns into new features that will help your model - often overlapping with data prep.
- Training: You evaluate different model architectures. Is it NLP? Regression? You test multiple approaches, compare accuracy, and tune hyperparameters (the configuration settings that control how a model learns before training starts).
- Deployment: This is its own can of worms - you need APIs, frontend integration, backend integration. If you are a small team, you might be writing all of it.
- Monitoring: Finally, you watch how the model performs in production. Is the accuracy sufficient for the business?
And then entropy hits. Your model accuracy degrades. The entire process starts over. All of it, manual. All of it, fragile.
MLOps: DevOps Principles for Machine Learning
MLOps (Machine Learning Operations, which is the practice of applying automation, testing, and deployment rules to machine learning) implements DevOps principles, tools, and practices into the machine learning workflow. It transforms the entire pipeline from manual and fragile to automated and reliable. The foundation is straightforward: everything is code. Your notebooks, your Python scripts, your data processing pipelines - all of it is code, and all of it belongs in a source code repository. This single decision opens the door to everything that comes next. From your repository, you can branch in two directions:
Direction 1 - Deployment CI/CD: Your deployment code (APIs, frontends) gets continuous integration and continuous deployment automation. Every commit automatically triggers builds and deployments.
Direction 2 - Training CI/CD: Your training code gets the same treatment. Every commit can automatically push a model to start training. You separate your training infrastructure (GPUs, parallel computation) from your deployment infrastructure (Docker containers, load balancers) because they are doing fundamentally different tasks.
Both directions feed into monitoring. In DevOps, monitoring tools ensure deployments stay live, rollouts happen correctly, and A/B tests show results. Apply the same concepts to your model: track accuracy, detect drift (the slow loss of predictive accuracy as real-world data patterns change), and set up automated triggers. For example, if accuracy drops below 80%, automatically kick off a new training process on fresh data. Using CI/CD and automation, the new model gets pushed to production without manual intervention.
After the GPU server disaster, I rebuilt the market research pipeline using MLOps principles. The training notebooks became versioned scripts in a Git repository. Feature engineering became a reproducible pipeline. Model training became a CI/CD job triggered by new data or accuracy degradation alerts. Deployment became a containerized API with automated rollback capabilities. The stress reduction was immediate. The model that previously took us weeks to retrain and deploy could now be updated in hours, with full auditability and zero risk of losing work to an expired server.
Real-World Implementation: Unifying MLOps Bias Prevention and Agent Governance
What is Agent Governance?
Agent Governance is the framework for controlling autonomous AI systems that take actions in the real world. It includes immutable activity logging (every decision is recorded in a tamper-proof ledger), tool execution guardrails (limiting what actions the agent can perform), human-in-the-loop escalation (requiring human approval for high-stakes decisions), and kill switches (the ability to immediately halt agent operations). For the full deep-dive, see our companion guide: How to Secure and Govern Autonomous AI Agents.
To see how these two paradigms operate in tandem, let us explore the design of an Automated Market Research Processor. This system employs a predictive machine learning model to evaluate product-market viability (the MLOps domain) and an autonomous AI agent to execute actions based on those viability scores, such as generating market entry reports or requesting additional competitive data (the Governance domain).
Without integrating both frameworks, two severe failure modes arise:
- The ML model could recommend products with systemic regional bias, which the agent blindly executes.
- The agent could publish a market report without verifying the model's fairness state, bypassing quality thresholds.
Unified Architecture & Topic Flow
Below is the visual roadmap showing how the MLOps Bias Shield and Agent Governance layers are structured to ensure absolute compliance and safety in a production environment.
Integrating Bias Mitigation and Execution Guardrails
Here is the production Python implementation used to enforce fairness before delegating execution to an autonomous AI agent. By calculating the Disparate Impact Ratio (DIR) in real-time, the processor intercepts biased trends. If the bias check fails, or if a high-stakes recommendation requires validation, the system downgrades the agent's autonomy to prevent downstream harm.
import numpy as np
from datetime import datetime, timezone
class TrustworthyMarketResearchProcessor:
def __init__(self, risk_model, fairness_threshold=0.8, window_size=500):
# Initialize model, EEOC four-fifths threshold, and rolling window size
self.model = risk_model
self.fairness_threshold = fairness_threshold
self.window_size = window_size
self.activity_log = []
# Real-time tracking arrays for pipeline monitoring
self.recent_predictions = []
self.recent_protected_flags = []
def evaluate_fairness(self):
"""
Computes the Disparate Impact Ratio (DIR).
DIR = (approval rate for unprivileged group) / (approval rate for privileged group)
"""
if len(self.recent_predictions) < 30:
return 1.0 # Insufficient statistical significance
preds = np.array(self.recent_predictions)
groups = np.array(self.recent_protected_flags)
privileged_mask = groups == 0
unprivileged_mask = groups == 1
if not privileged_mask.any() or not unprivileged_mask.any():
return 1.0
privileged_rate = preds[privileged_mask].mean()
unprivileged_rate = preds[unprivileged_mask].mean()
if privileged_rate == 0:
return 1.0
return unprivileged_rate / privileged_rate
def process_application(self, applicant_data, protected_group_flag):
"""
Main execution pipeline incorporating the MLOps Bias Shield.
"""
risk_score = float(self.model.score(applicant_data))
approved = 1 if risk_score < 0.3 else 0
# Step 1: Pre-execution fairness check to prevent cascading bias
dir_score = self.evaluate_fairness()
if dir_score < self.fairness_threshold:
outcome = "blocked"
elif applicant_data.get("market_value", 0) > 50000:
outcome = "escalated"
else:
outcome = "recommend" if approved else "skip"
# Step 2: Immutable compliance logging
self.activity_log.append({
"applicant_id": applicant_data.get("id"),
"risk_score": risk_score,
"recommendation": outcome,
"protected_group": protected_group_flag,
"dir_score": round(dir_score, 4),
"timestamp": datetime.now(timezone.utc).isoformat()
})
# Step 3: Update statistical window (excluding system blocks)
if outcome != "blocked":
self.recent_predictions.append(approved)
self.recent_protected_flags.append(protected_group_flag)
self.recent_predictions = self.recent_predictions[-self.window_size:]
self.recent_protected_flags = self.recent_protected_flags[-self.window_size:]
if outcome == "blocked":
return f"BLOCKED: Bias Alert (DIR={dir_score:.2f}, threshold={self.fairness_threshold})"
elif outcome == "escalated":
return "ESCALATED: Human Review Required"
return "Recommended" if approved else "Skipped"
Frequently Asked Questions
What are the five pillars of trustworthy AI?
The five pillars are Fairness (ensuring equitable treatment for all groups), Explainability (ability to describe how decisions are made), Robustness (resistance to adversarial attacks and manipulation), Transparency (disclosing that AI is being used and providing model metadata), and Data Privacy (protecting the personal data used in training and inference).
What is the difference between an AI hallucination and a statistical error?
The term "hallucination" anthropomorphizes AI by implying the model is experiencing something. In reality, what happens is a statistical error - the model predicts the next most syntactically correct word sequence, not the most factually accurate answer. It can generate entirely fabricated information that sounds convincing because fluency and accuracy are different properties in language models.
How does MLOps differ from traditional model development?
Traditional model development is manual - data prep, training, deployment, and monitoring are all separate, fragile processes. MLOps applies DevOps principles (source control, CI/CD, automated testing, monitoring) to the entire ML workflow, making training reproducible, deployment automated, and monitoring continuous. This addresses the fact that 60-80% of manually developed models never reach production.
Why is team diversity critical for AI development specifically?
The "Wisdom of Crowds" mathematical model proves that diverse groups produce more accurate collective judgments. In AI, homogeneous teams create blind spots in training data selection, bias auditing, and impact assessment. A diverse team considering gender, race, ethnicity, age, neurodiversity, and worldview is statistically more likely to identify and prevent harmful biases before deployment.
What is an indirect prompt injection and why is it dangerous?
An indirect prompt injection occurs when a third party alters a website or data source by adding hidden content designed to manipulate an AI's behavior. Unlike direct jailbreaking, this attack is invisible to the end user. The AI processes the hidden instructions and potentially executes malicious actions - such as sending harmful content or leaking private data - without anyone being aware that the system has been compromised.
What is "Tech Ethics by Design" and how does it work?
Tech Ethics by Design is a three-step systemic empathy framework embedded during the evaluation phase of AI projects. Step 1 (Layers of Effect) maps primary, secondary, and tertiary (unintended) effects. Step 2 (Dichotomy Mapping) separates tertiary effects into potentially beneficial and potentially harmful categories. Step 3 (Ethical Hacking) defines organizational principles, end-user rights, and specific mitigations for identified harms - all before any code is written.
What is the environmental cost of training large language models?
Training a brand new large language model produces as much carbon dioxide as over 100 roundtrip flights between New York and Beijing. This significant environmental footprint underscores the importance of responsible model development, including evaluating whether a new model needs to be trained from scratch versus fine-tuning existing models or using transfer learning.